고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
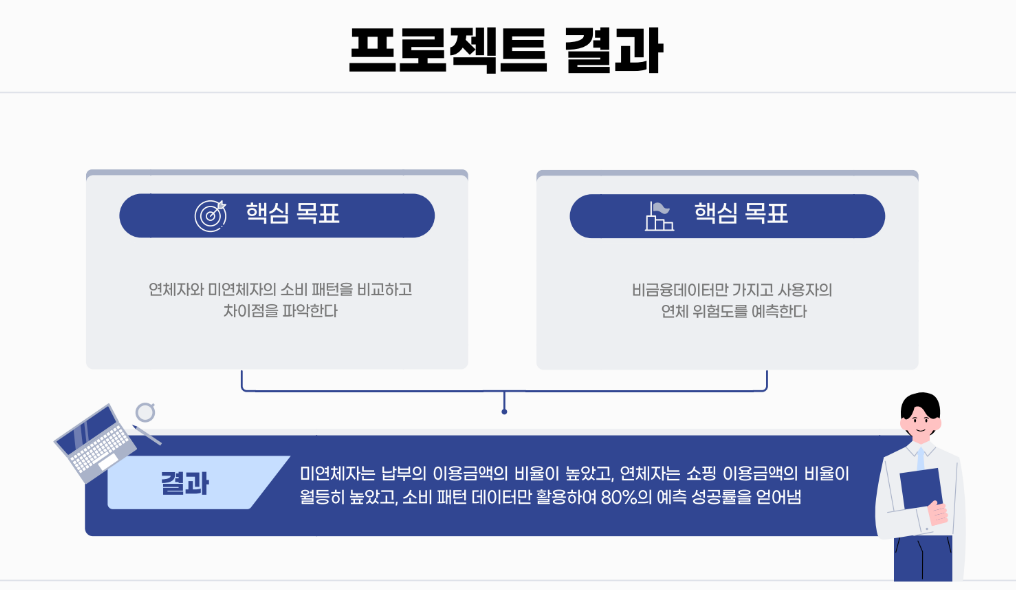
비금융 데이터 중 업종별 이용 금액과 횟수에 중점을 두어 연체 위험도를 예측하는 과제를 마무리하였다.
Pipe Line

Data Flow

1. Processed Data: 전처리된 데이터를 사용하여 모델링을 진행한다.
2. Prepare Data: 데이터를 훈련 세트와 테스트 세트로 나눈다. 모델 학습과 검증을 위해 데이터를 준비한다.
3. Parameter Tuning: 모델들에 대해 최적의 하이퍼파라미터를 찾기 위한 튜닝 작업을 진행한다. (축소 데이터 셋 사용.)
4.Tuned Model w/ Best Params: 최적의 하이퍼파라미터가 적용된 모델이 준비된다.
5. Model Evaluation: 각 모델을 평가하고 성능을 비교한다.
6. Best Model: 성능 평가 결과를 바탕으로 가장 우수한 모델을 선택한다
7. Train, Test Set (Total Data): 최적의 파라미터로 설정된 모델을 전체 데이터를 사용하여 학습하고 테스트한다.
8. Predictions: 모델이 예측한 결과를 출력한다.
위의 과정으로 이루어지는 Pipe Line을 구성했다.
다른 로컬 환경에서 git clone을 했을 때, 전체 pipeline 이 실행되도록 만드는 것이 모델링의 주요 목적이다.
- mlflow를 이용해 run의 중간 파일들을 artifacts에 log 한다.
=> 이때, run id를 임시 텍스트 파일로 저장한다
- 이후의 run에서 중간 파일들을 사용하고자 할 때:
=> 해당 파일을 artifact로 가지고 있는 run의 id 조회
=> run id를 통해 artifact에 접근하고 파일을 load
데이터 수집 및 EDA

AI-Hub
[교통물류] 상용 자율주행차 야간 도심도로 데이터 #자율주행차 # 상용 자율주행 # 상용 자율주행차 # 자율주행 데이터 #자율주행 조회수 11,572 관심등록 10 다운수 131
www.aihub.or.kr
저희는 Ai-Hub에서 제공하는 데이터를 사용했다.
연체 잔액 즉 Target을 [0(~100,000),1( 100,000 ~ 1,000,000 ),2( 1,000,000 ~ )]으로 특정했다.
10만 원 이상의 금액을 5일 이상 연체하면 단기연체정보가 신용평가회사에 등록되어 금융회사에 공유된다는 업계의 기준에 맞추어서 진행했다.


처음 데이터를 받았을 때 약 Column : 150 , Row : 3,000,000의 상대적으로 크기가 큰 데이터였기 때문에
목표와 맞는 의미 있는 Column을 솎아내는 것이 주요 포인트였다.
고객의 인구통계학적 특성, 소비패턴 관련 변수를 골라내고 결측치가 상당수를 차지하는 Column을 제거하였다.
조 전체적으로 금융 관련 도메인이 좋은 상황은 아니었기에 Column의 의미를 파악하기에 제법 오랜 시간을 사용하였다.

다행히 데이터에 칼럼명세서가 같이 제공되어서 쉽게 해결할 수 있었다.
랜덤 포레스트(Random Forest), XGBoost, LightGBM 같은 트리 기반의 모델을 사용할 예정이기 때문에
효율적인 데이터 처리를 위해서 범주형 데이터에 라벨링을 수행하였다.

라벨링은 선형 모델이나 신경망과 같은 모델에서는 주의해서 사용해야 하며
범주를 0부터 시작하는 숫자로 매핑하는 간단한 방식이다.
하지만 범주 간의 관계나 순서가 없는 데이터에 순서를 부여할 수 있기 때문에, 모델이 잘못된 관계를 학습할 위험이 있다.
범주 간의 관계가 중요하지 않거나 트리 기반 모델을 사용한다면 괜찮다.
https://devmin67.tistory.com/22
한경 X Toss - semi project
이 글은 한경 x Toss bank 과정 중 진행한 semi project에 대한 전반적인 과정 및 맡은 역할(EDA)에 대한 리뷰입니다.프로젝트 일정: 2024년 08월 19일 ~ 2024년 09월 06일 프로젝트 주제는 다음과 같습니다.
devmin67.tistory.com
전처리 팀의 리뷰
범주형 데이터가 아닌 연속형 변수들은 standard scaling을 진행하고
PCA를 진행하여 다중공선성 문제, 차원의 저주, 노이즈 문제를 해결하였다.
PCA는
1) 변수 선택(Feature Selection) : 현재 존재하는 변수 중 결괏값을 잘 표현할 수 있는 변수를 고르는 것
2) 변수 추출(Feature Extraction) : 변수들을 조합해 새로운 변수를 만들어 결괏값을 잘 표현하는 방법
기존의 변수들을 선형 결합(linear combination)하여 새로운 변수를 만들어 내는 기법이라고 할 수 있겠다
발표 때 PCA에 대해서 질문을 많이 받았는데, 단순 차원 축소와 데이터 설명력에 대해서만 설명을 드린 거 같아서 아쉬움이 크다.


PC 축 별 누적 데이터 설명력을 시각화한 그래프이다.
Scree Plot의 팔꿈치 부분은 4번째이지만,
3개의 축으로 76.8%의 데이터를 설명하였으며, 4번째 축을 추가하여도 6% 정도의 설명력이 증가하기 때문에
3번째 축까지 사용하는 것이 더 효율적이라고 생각하여, 3번째 축까지 사용하였다.

각 축에 대해 어떤 Column이 더 높은 가중치를 받았는지에 대한 단순 내림차순이다.
알고리즘이 가중치를 선정하는 기준을 알 수는 없지만 어떤 칼럼이 더 영향을 주었는지 보여주기 위해 추가하였다.


모델을 돌리기 전에 전처리 된 데이터를 시각화해보았다.
20대 연체자 중 '쇼핑' 항목이 높은 사람이 연체 확률이 높을 수 있다는 추론을 할 수 있다.
또한 미연체자는 교통과, 납부, 해외에 소비를 많이 하는 확률이 상대적으로 높다는 추론 또한 해볼 수 있다.
이 부분에서 20대는 교통, 납부 부분에서 부모님이 책임을 져주시는 경우가 많기 때문에 20대의 연체율을 예측하는 데에 과연 적절한 수치인가? 에 대한 질문을 받았다.
그리고 우리가 나눈 카테고리에서 '쇼핑'이 높게 나오는 건 당연한 거 아닌가 연체자 만의 특성이 맞는가에 대한 질문도 받았다.
그 부분까지는 고려하지 못한 게 맞아서 보안을 해야 한다.
아무래도 쇼핑 부분을 더 세밀하게 나누어서 어떤 쇼핑을 주로 하는가. 또 '요식' 카테고리가 너무 낮게 나오는 것으로 보아 '쇼핑'에 흡수된 것으로 보이기에 주어진 칼럼 안에서 분류할 수 있는지에 대해서도 확인이 필요해 보인다.
또 결측치가 너무 많이 나오기 때문에 1순위 업종만 사용해서 소비패턴을 예측하였는데, 2순위, 3순위 업종을 모두 파악해서 진행하는 방향도 고려해 봐야 한다.

랜덤 포레스트 (Random Forest)
랜덤 포레스트(Random Forest)는 앙상블 학습 기법의 대표적인 예로, 다수의 의사결정 트리(Decision Trees)를 결합하여 예측 성능을 향상하는 모델이다. 개별 의사결정 트리는 본질적으로 직관적이지만, 단일 트리는 학습 데이터에 과적합(overfitting)되기 쉽다. 랜덤 포레스트는 이러한 문제를 해결하기 위해 다수의 트리를 학습하고, 각 트리의 예측 결과를 투표 방식(분류) 또는 평균 산출(회귀)을 통해 최종 결과를 도출한다.
랜덤 포레스트의 주요 특징 중 하나는 **배깅(Bootstrap Aggregating)**을 활용한다는 점이다. 배깅은 원본 데이터에서 랜덤 하게 서브셋을 생성하여 각 트리를 독립적으로 학습시키는 기법으로, 개별 트리들이 학습하는 데이터가 상이하기 때문에 모델의 **편향-분산 트레이드오프(Bias-Variance Tradeoff)**를 개선한다. 또한, 랜덤 포레스트는 **특징 무작위성(Random Feature Selection)**을 적용하여 각 트리에서 일부 특징만을 무작위로 선택해 학습함으로써 상호 간의 의존성을 줄이고 다양성을 극대화한다.
이러한 구조 덕분에 랜덤 포레스트는 다음과 같은 강점을 갖는다:
- 과적합 방지: 다수의 트리 결과를 평균화하거나 투표함으로써 단일 트리보다 과적합 위험이 낮다.
- 견고한 성능: 데이터의 노이즈와 결측치에 강하며, 다양한 데이터셋에서 일관되게 좋은 성능을 발휘한다.
- 특징 중요도 제공: 랜덤 포레스트는 각 특징의 중요도를 평가해 제공할 수 있어, 모델 해석 가능성을 높인다.
그러나 트리 수가 많아질수록 모델이 복잡해지고 계산 비용이 증가할 수 있기 때문에 대규모 데이터에 대해서는 최적화가 필요할 수 있다.
XGBoost
**XGBoost(Extreme Gradient Boosting)**는 성능과 효율성을 동시에 추구하는 트리 기반 부스팅(Boosting) 알고리즘이다. 부스팅은 약한 학습기(weak learners)들을 연속적으로 학습시키면서 각 학습기의 오차를 보정하는 방식으로, XGBoost는 이 과정을 더욱 최적화한 모델이다.
XGBoost는 다양한 최적화 기법을 적용하여 기존 부스팅 모델 대비 더 빠르고, 더 강력한 성능을 자랑한다. 그 주요 특징으로는:
- 정교한 손실 함수 최적화: XGBoost는 손실 함수의 **2차 미분(Hessian)**까지 고려한 정교한 방법을 사용하여 학습 속도를 높이고 예측 성능을 개선한다.
- 규제(Regularization): 과적합을 방지하기 위해 L1, L2 정규화를 지원하여 모델의 복잡성을 제어한다.
- 스파스 데이터 처리: XGBoost는 결측값 또는 희소행렬을 효과적으로 처리할 수 있어, 실제 데이터에서 자주 발생하는 문제를 해결할 수 있다.
- 병렬 처리: XGBoost는 트리 분할 및 노드 확장을 병렬 처리할 수 있어, 대규모 데이터셋에서 빠른 학습 속도를 보장한다.
이러한 특징 덕분에 XGBoost는 Kaggle과 같은 데이터 과학 경진대회에서 자주 채택되며, 특히 복잡한 데이터셋이나 대규모 데이터셋에서 매우 우수한 성능을 발휘한다. 그러나 XGBoost는 하이퍼파라미터의 최적화에 상당한 시간이 소요될 수 있기 때문에, 자동화된 튜닝 도구를 활용하는 것이 권장된다.
LightGBM
**LightGBM(Light Gradient Boosting Machine)**은 XGBoost와 유사한 부스팅 알고리즘이지만, 더 경량화되고 최적화된 형태로 대규모 데이터셋에 적합한 모델이다. LightGBM은 특히 대규모 데이터 처리에서 학습 속도와 메모리 효율성을 극대화한 것이 특징이다.
LightGBM은 몇 가지 중요한 차별점을 통해 XGBoost와 구별된다:
- 리프 중심 트리 분할(Leaf-Wise Growth): LightGBM은 트리의 노드를 수평으로 확장하는 수준별(Level-wise) 분할 대신, 리프 노드 중심으로 성장을 최적화하여 더 깊고 복잡한 트리를 생성한다. 이로 인해 정확도는 높아지지만, 과적합 위험도 존재할 수 있어 하이퍼파라미터 조정이 필수적이다.
- Gradient-based One-Side Sampling (GOSS): 전체 데이터를 사용하지 않고도 중요한 데이터 포인트만을 샘플링하여 성능을 유지하면서 연산 속도를 높이는 기법이다.
- Exclusive Feature Bundling (EFB): LightGBM은 상호 간섭이 적은 특징들을 하나로 묶어, 다차원 데이터에서도 메모리 사용을 효율적으로 줄일 수 있다.
LightGBM은 메모리 사용량이 제한적이거나 대규모 데이터셋을 빠르게 처리해야 하는 상황에서 특히 효과적이며, XGBoost보다 더 빠른 학습 속도를 제공한다. 다만, Leaf-wise 방식 때문에 과적합 위험이 존재할 수 있으며, 이에 대한 적절한 제어가 필요하다.

XGBoost가 대부분의 지표에서 가장 우수한 성능을 보였으며, 특히 Precision(정밀도), Recall(재현율), ROC-AUC에서 두드러진다. LightGBM도 전반적으로 높은 성능을 보이며, 특히 로그 손실(Log Loss)에서 XGBoost와 거의 비슷한 성과를 냈다. 랜덤 포레스트는 다른 두 모델에 비해 성능이 조금 떨어지지만, 여전히 비교적 우수한 결과를 보여준다.
XGBoost가 가장 우수한 성능을 보였기 때문에 전체 데이터를 진행해 보았다.

역시 우수한 성능을 보여준다.

첫 프로젝트이기 때문에 아쉬운 점도 많고 부족한 점도 많지만,
그만큼 많이 배운 것 같다.
728x90
반응형
'경험 리뷰 > 한국경제 with Tossbank' 카테고리의 다른 글
| Deep Learning 공부하기 ( 2 ) (1) | 2024.09.19 |
|---|---|
| Deep Learning 공부하기 ( 1 ) (7) | 2024.09.19 |
| 한국 경제신문 with toss bank - 중간 프로젝트_( 2 ) (2) | 2024.09.02 |
| 한국 경제신문 with toss bank - 중간 프로젝트_( 1 ) (4) | 2024.09.01 |
| 랜덤 포레스트 ( Random Forest ) (0) | 2024.08.29 |




