고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
저희조는 비금융 데이터 그 중에서 업종별 이용 금액과 횟수에 중점을 두어
연체 위험도를 예측하는 과제를 수행하였습니다.
금융_합성 데이터에서
1. 회원 정보
2. 신용 정보
3. 승인 매출 정보를 활용하였습니다.
데이터는 '카드 발급 회원번호'를 기준으로 merge 하였습니다.
소비 패턴을 분석하여 신용도를 예측하는게 목표 입니다.
연체 위험도(타겟 값)을 [0, 1, 2]로 선정하였고
기준은
0 => 100,000 이하
1 => 100,000 초과 1,000,000 이하
2 => 1,000,000 초과로 선정 하였습니다.
100,000원 이하로 기준을 정한 이유는, 10만 원 이상의 결제액이 영업일 기준으로 5일 이상 미납될 경우, 카드사와 금융기관에 미납 정보가 공유되기 때문입니다.
소비 패턴 분석을 위해 쇼핑, 요식, 교통, 의료, 납부, 교육, 여유생활, 사교활동, 일상생활, 해외 등의 카테고리로 그룹화하였으며, 이를 통해 1순위, 2순위, 3순위 업종과 각 순위별 이용 금액을 추적하여 연체 잔액을 기준으로 저희가 만든 위험도를 예측하는 것이 목표입니다.
다만, 이번 프로젝트에는 단순 당월 연체 금액만을 기준으로 위험도를 나눈 점과 신빙성이 부족한 자체 제작 연체 위험도 등 여러 한계가 있습니다.
저의 첫번째 프로젝트이기에 양해 부탁드리겠습니다..
도메인의 중요성 그리고 저의 현 위치를 절실히 느낀 2주 였습니다람쥐.
다들 너무 잘하기 때문에,,
저는 남는게 시간이기 때문에 과정이 끝나기 전에 보강 해보도록 하겠습니다.
저는 PCA와 모델링 역할을 맡았으며, 오늘은 제가 작업한 PCA에 대해 리뷰를 남기고, 코드 정리를 하겠습니다.
PCA 란? 그리고 수행 목적.
대표적인 차원 축소 기법으로는 머신러닝, 데이터 마이닝, 통계 분석, 노이즈 제거 등 다양한 분야에서 사용됩니다. 이 기법은 기존 데이터 구조를 최대한 유지하면서 차원을 축소하는 것이 목표이며, 이를 위해 데이터의 분산이 최대가 되는 방향의 벡터를 찾습니다.


왼쪽보다는 오른쪽 벡터에서 빨간색 점들이 더 넓게 분포되어 있습니다. 즉, '왼쪽 이미지'에서는 분산이 낮고, '오른쪽 이미지'에서는 분산이 높다고 볼 수 있습니다. 두 이미지 모두 기존 데이터의 일부 정보를 상실했지만, 그럼에도 불구하고 기존 구조를 최선으로 유지한 것은 오른쪽 이미지라고 할 수 있습니다.
PCA 알고리즘은 "데이터를 사영한 후, 분산이 최대가 되도록 하는 벡터를 찾는 과정"입니다. 이 방법은 2차원, 3차원, 그 이상에서도 동일하게 적용됩니다.
분산이 최대가 되는 방향을 PC1이라고 하며, PC1과 수직이면서 그다음으로 분산이 최대가 되는 벡터를 PC2라고 합니다.
사영된 데이터들은 직선 위에 존재한다고 가정하지만, 때로는 곡선을 따라 사영될 때 데이터 구조를 더 잘 유지할 수 있는 경우도 있습니다. 기본적인 PCA는 이러한 비선형 패턴을 잡아내지 못하지만, 이러한 비선형 패턴을 처리할 수 있는 non-linear PCA 기법도 존재한다고 합니다.

NLPCA - nonlinear PCA - auto-associative neural networks - autoencoder bottleneck neural networks - Matthias Scholz
Nonlinear principal component analysis (NLPCA) is commonly seen as a nonlinear generalization of standard principal component analysis (PCA). It generalizes the principal components from straight lines to curves (nonlinear). Thus, the subspace in the origi
www.nlpca.org
,,, 나중에 더 찾아보겠습니다.
나의 PCA 작업 과정.
PCA는 데이터 변수들 간의 분산을 기반으로 주성분을 찾아내는 기법입니다. 이때, 각 변수의 스케일이 다를 경우, 스케일이 큰 변수가 주성분 분석에 과도한 영향을 미칠 수 있습니다. 예를 들어, 수치의 범위가 큰 변수는 상대적으로 더 중요한 요소로 인식되기 쉽습니다.
모든 변수를 공정하게 평가하기 위해, 변수들을 동일한 스케일로 맞추는 것이 중요합니다. 일반적으로 StandardScaler를 사용해 데이터를 평균이 0, 분산이 1인 표준 정규 분포로 변환합니다.
또한 데이터에 원핫 인코딩된 변수들이 포함되어 있을 때, 스케일링을 직접 적용하면 값이 왜곡될 가능성이 있습니다.
수치형 데이터와 범주형 데이터를 분리하여 각각 따로 스케일링한 후, 다시 합치는 방법을 사용하였습니다.
# 스케일링할 컬럼 목록
columns_to_scale = [
'이용금액_업종기준', '이용금액_쇼핑', '이용금액_요식', '이용금액_교통',
'이용금액_의료', '이용금액_납부', '이용금액_교육', '이용금액_여유생활',
'이용금액_사교활동', '이용금액_일상생활', '이용금액_해외',
'_1순위업종_이용금액', '_2순위업종_이용금액', '_3순위업종_이용금액',
'_1순위쇼핑업종_이용금액', '_2순위쇼핑업종_이용금액', '_3순위쇼핑업종_이용금액',
'_1순위교통업종_이용금액', '_2순위교통업종_이용금액', '_3순위교통업종_이용금액',
'_1순위여유업종_이용금액', '_2순위여유업종_이용금액', '_3순위여유업종_이용금액',
'_1순위납부업종_이용금액', '_2순위납부업종_이용금액', '_3순위납부업종_이용금액',
'이용금액_온라인_R6M', '이용금액_오프라인_R6M', '이용금액_온라인_R3M',
'이용금액_오프라인_R3M', '이용금액_페이_온라인_R6M', '이용금액_페이_오프라인_R6M',
'이용금액_페이_온라인_R3M', '이용금액_페이_오프라인_R3M',
'이용금액_간편결제_R6M', '이용금액_A페이_R6M', '이용금액_B페이_R6M',
'이용금액_C페이_R6M', '이용금액_D페이_R6M', '이용금액_간편결제_R3M',
'이용금액_A페이_R3M', '이용금액_B페이_R3M', '이용금액_C페이_R3M', '이용금액_D페이_R3M',
'RP금액_B0M', '이용가맹점수', '이용건수_온라인_R6M', '이용건수_오프라인_R6M',
'이용건수_온라인_R3M', '이용건수_오프라인_R3M',
'이용건수_오프라인_R3M', '이용건수_페이_온라인_R6M', '이용건수_페이_오프라인_R6M',
'이용건수_페이_온라인_R3M', '이용건수_페이_오프라인_R3M',
'이용건수_간편결제_R6M', '이용건수_A페이_R6M', '이용건수_B페이_R6M',
'이용건수_C페이_R6M', '이용건수_D페이_R6M', '이용건수_간편결제_R3M',
'이용건수_A페이_R3M', '이용건수_B페이_R3M', '이용건수_C페이_R3M',
'이용건수_D페이_R3M'
]
# 스케일링할 데이터만 추출하여 새로운 DataFrame 생성
continuous_df = ui_df[columns_to_scale]
# StandardScaler를 사용하여 데이터 스케일링
scaler = StandardScaler()
scaled_continuous_df = pd.DataFrame(
scaler.fit_transform(continuous_df),
columns=continuous_df.columns
)
# 모든 행과 열을 출력하도록 설정
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
# 스케일링된 데이터 확인
print(scaled_continuous_df.head())
나중에 제외된 칼럼들을 다시 합쳐주기 위해 새로운 DF를 생성 합니다.
# 모든 컬럼 중에서 'columns_to_scale'에 포함되지 않은 컬럼 선택
columns_to_keep = ui_df.columns.difference(columns_to_scale)
# 해당 컬럼들로 새로운 DataFrame 생성
remaining_df = ui_df[columns_to_keep]
# '발급회원번호' 컬럼을 remaining_df에 추가
remaining_df = pd.concat([ui_df[['발급회원번호']], remaining_df], axis=1)
# 모든 행과 열을 출력하도록 설정
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
# 새로운 DataFrame 확인
print(remaining_df.head())
Explained Ratio = n번째 고유값 / 고유값의 총합
이는 주어진 차원을 줄이더라도 원본 데이터의 분산을 얼마나 보존할 수 있는지를 수치적으로 나타내는 지표입니다. 이 비율은 각 주성분이 원본 데이터의 분산을 얼마나 설명할 수 있는지를 나타내며, 차원 축소 과정에서 정보 손실을 최소화하기 위해 중요한 역할을 합니다.
몇 개의 주성분을 선택할지 판단하기 위해서는 스크리 플롯(Scree Plot)을 생성하여 시각적으로 확인하는 것이 좋습니다. 스크리 플롯은 주성분의 고유값을 크기 순으로 나열한 그래프로, 각 주성분이 얼마나 많은 분산을 설명하는지를 보여줍니다.
일반적으로, 스크리 플롯에서 고유값의 감소 속도가 급격히 줄어드는 지점을 찾아, 그 지점의 주성분 수에서 1을 뺀 값을 최적의 주성분 개수로 선택하는 것이 좋다고 합니다. 이 방법을 통해 불필요한 차원을 줄이면서도, 중요한 정보는 최대한 유지할 수 있습니다.
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# PCA 수행
pca = PCA()
pca.fit(scaled_continuous_df)
# 스크리 플롯 생성
plt.figure(figsize=(10, 6))
plt.plot(
range(1, len(pca.explained_variance_ratio_) + 1),
pca.explained_variance_ratio_,
marker='o',
linestyle='--'
)
plt.title('Scree Plot')
plt.xlabel('Principal Component')
plt.ylabel('Explained Variance Ratio')
plt.show()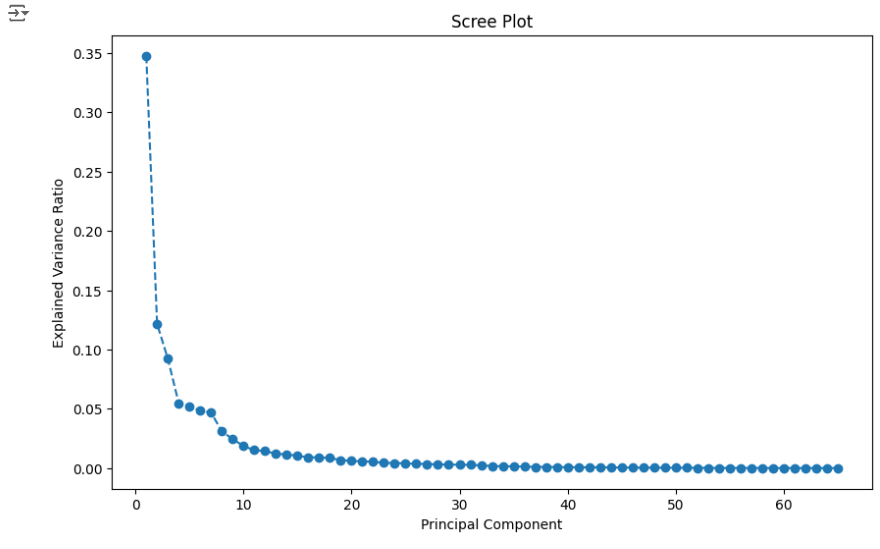
3개로 진행 하였습니다.
# 주성분의 수를 결정 (예: 3개로 축소)
pca = PCA(n_components=3)
pca_transformed = pca.fit_transform(scaled_continuous_df)
# 3개의 주성분에 맞는 열 이름 생성
columns = [f'PC{i+1}' for i in range(3)]
# PCA 결과를 DataFrame으로 변환
pca_df = pd.DataFrame(pca_transformed, columns=columns)
# 변환된 DataFrame 확인
print(pca_df.head())# PCA 결과 확인
print(pca_df.head())
# 기존의 discrete 데이터와 PCA 결과를 결합
final_df_with_discrete = pd.concat([remaining_df, pca_df], axis=1)
# 결합된 최종 DataFrame 확인
print(final_df_with_discrete.head())
target 데이터를 불러와서 확인 합니다.
# CSV 파일을 읽어와 DataFrame으로 변환
t_df = pd.read_csv(FILE_PATH2)
# 모든 행과 열을 출력하도록 설정
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
# DataFrame의 첫 5개 행 확인
t_df.head()# '발급회원번호'를 기준으로 final_df_with_discrete와 t_df를 내부 조인하여 병합
merged_df = pd.merge(final_df_with_discrete, t_df, on='발급회원번호', how='inner')# 병합된 DataFrame의 컬럼 이름들 출력
print(merged_df.columns)
참고자료
https://gguguk.github.io/posts/PCA/
PCA(주성분 분석)
원래 데이터들을 어느 벡터에 사영시켜야 데이터의 구조를 최대한 보존할 수 있을까?
gguguk.github.io
https://deep-jin.tistory.com/entry/PCA-Principal-Component-Analysis
PCA (Principal Component Analysis)
PCA (Principal Component Analysis) PCA는 데이터 분석을 위한 전처리 과정에서 차원을 축소(dimension reduction)하기 위해 사용되는 기법입니다. 상관관계가 있는 변수끼리 가중선형결합(weighted linear combination)
deep-jin.tistory.com
https://www.youtube.com/watch?v=vDSNsZXOzTM&t=40s
728x90
반응형
'경험 리뷰 > 한국경제 with Tossbank' 카테고리의 다른 글
| 한국 경제신문 with toss bank - 중간 프로젝트_( 3 ) (5) | 2024.09.08 |
|---|---|
| 한국 경제신문 with toss bank - 중간 프로젝트_( 2 ) (2) | 2024.09.02 |
| 랜덤 포레스트 ( Random Forest ) (0) | 2024.08.29 |
| Git 기본 개념 이해하고 관리하기 (2) | 2024.08.29 |
| GitHub에서 Repository 생성 후 Jupyter Lab 환경 설정하기 (0) | 2024.08.25 |




