고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
RNN(Recurrent Neural Network)
시퀀스 : 문장 같은 단어가 나열된 것을 의미
시퀀스 모델 : 이러한 시퀀스들을 처리하기 위해 고안된 모델. 그 중 RNN은 딥 러닝의 가장 기본적인 시퀀스 모델이다.
시계열 데이터를 학습하고, 예측하기 위한 알고리즘
- 사람이 사용하는 문장도 시계열 데이터 이다.
- 단어의 등장 순서가 바뀌면 의미 자체가 바뀌어 버리는 경우도 많기 때문에 자연어 처리에서 시계열 모델이 활용.
Ex. Apple 빼고 다른 주식이 올랐다. vs 다른 주식 빼고 Apple이 올랐다.



RNN은 기본적으로 순서의 흐름에 따른 정보를 학습하는 네트워크 이다.
일반 FCN(Fully Connected layer)는 순서에 대한 개념이 없기 때문에 단어 벡터 자체만을 이용해 훈련 하는 것은 문제 없으나, 단어 배치 순서에 따른 문맥에 대한 파악이 부족하다.
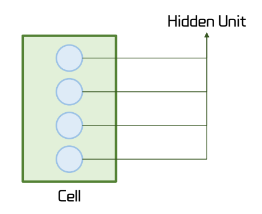
RNN은 Cell이란 특수한 구조를 이용하여 시간적인 정보를 유지하며 학습한다.
Cell은 이전의 값을 기억하려고 하는 일종의 메모리 역활을 수행 하므로 Memory Cell이라고 부른다.
은닉층의 메모리 셀에서 나온 값이 다음 은닉층의 메모리 셀에 입력된다. 이 값을 '은닉 상태'라고 한다.
Cell은 Hidden Unit이 존재하며, FCN의 레이어와 비슷한 역활을 한다.

--입력--
Xt : 현 시점의 입력 값
Ht-1 : 이전 시점의 hidden state
-- 출력 --
Ht : 현재 시점의 상태
Y^t : 현재 상태의 결과

시간(순서)을 의미하는 t가 총 4개라고 했을 때, 다음과 같은 방법으로 RNN은 학습을 수행한다.
- 여러 입력이 들어와 제일 마지막 timestep에서 출력을 내는 방식을 Many to One 방식이라고 한다.
- t번 반복을 한다고 Cell이 t개가 생기는 것이 아니다. 하나의 Cell에서 t번의 연산이 일어난다.

Hidden state의 의미


Hidden state는 RNN이 이전 시점의 정보를 기억하고 있는 상태를 의미 한다.
- 시계열 데이터를 처리할 때 과거의 정보를 유지하며 현재 시점의 출력을 결정하는데 중요한 역활을 하기 때문이다.
텍스트와 RNN
텍스트 데이터도 단어 배치의 순번이 있기 때문에 시퀀스 데이터 이다. -> 임베딩 하여 RNN의 입력으로 사용 가능하다.
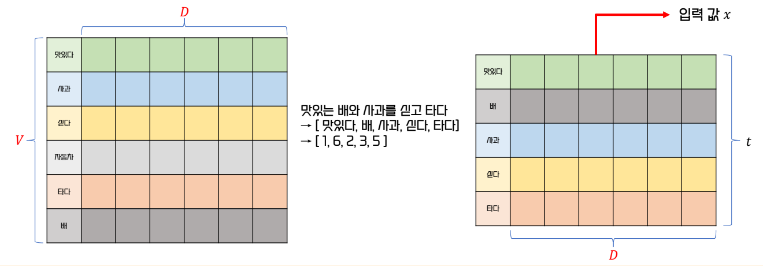
정수 인코딩 된 단어를 Embedding Layer에서 선택하면 순서에 맞게 Project Layer가 생성 된다.
이 Projection Layer가 RNN Cell 입력 데이터 x로 활용된다.

RNN을 사용하기 위한 데이터의 구조
똑같은 RNN 구조를 사용한다 하더라도 목적에 따라 데이터 세트의 구조가 달라진다.
입력 또는 출력 중 하나라도 순차데이터라면, RNN을 이용해 학습할 수 있다.

RNN은 입력과 출력의 길이를 다르게 설계할 수 있다.
1. 일 대 다 ( One - To - Many )

하나의 입력에 대해 여러 개의 출력을 가지는 일 대 다 모델.
시계열 데이터의 예측, 감정 분석, 번역 등에 사용된다.
2. 다 대 일 ( Many - To - One )

여러 개의 입력에 대해 한 개의 출력을 생성하는 모델.
에측, 상태 감지(장애 감지), 경고(데이터 기반 경보 발생) 발생, 감성 분류, 스팸 메일 분류 등에 사용된다.
3. 다 대 다 ( Many -To - Many )
여러 개의 입력에 대해 여러 개의 출력을 생성하는 모델.
비디오 분류, 이미지 캡셔닝, 게임 AI, 챗봇, 번역기 등에 사용된다.

https://casa-de-feel.tistory.com/39
딥 러닝의 가장 기본적인 시퀀스 모델 RNN (Recurrent Neural Network)
안녕하세요! 오늘은 자연어 처리에서 많이 쓰이는 딥 러닝의 가장 기본적인 시퀀스 모델인 RNN에 대해 알아보겠습니다. 1. RNN이란? 2. RNN의 학습 3. 바닐라 RNN의 한계 1. RNN이란? RNN이란 Recurrent Neural
casa-de-feel.tistory.com
-- 사진 참고 --
RNN 학습
+ RNN의 학습에는 back propagation의 확장인 BPTT가 사용 됩니다.
BPTT (Back Propagation Through Time) 는 RNN (Recurrent Neural Network) 의 학습을 위한 오차 역전파 방식입니다. RNN은 일반적인 신경망 (FCN) 과 다르게, 시간에 따라 반복되는 구조를 가지고 있어, 하나의 셀(Cell)이 여러 시점의 정보를 처리하게 됩니다.

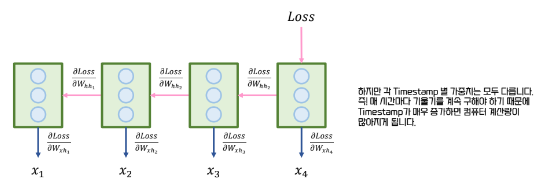

+ 정리 하자면
RNN의 반복적인 구조를 시간에 따라 펼쳐서 각 시점의 연산을 연결하고, 현재 시점의 에러를 과거 시점으로 전파하여 학습한다. 이를 통해 과거 상태들이 현재 결과에 미친 영향을 계산하고, 각 시점의 기울기 정보를 모아 하나의 가중치를 업데이트한다.( "동일한 가중치를 사용" ) 결국, BPTT는 시간에 따른 기울기 변화를 추적하여 RNN의 가중치를 효율적으로 조정하는 방식이다.
기본적으로 BPTT는 시간을 펼쳐서 과거부터 현재까지의 모든 시점에 대한 오차를 역전파하면서 학습을 진행한다.
하지만 시퀀스가 길어질수록 계산 비용이 기하급수적으로 증가하고, 메모리 사용량도 매우 커지게 된다.
+ Truncated BPTT가 있다.

Truncated BPTT는 시퀀스가 너무 길어지면 컴퓨터의 연산량이 매우 많아지는 단점을 극복하기 위해, 전체 timestep을 쪼개서 하나의 단위를 만들고, 그 단위마다의 가중치를 평균내서 업데이트 하는 방법이다.
- 한 번에 저장해야 하는 기울기의 수가 줄기 때문에 메모리 사용량의 이점
- 짧은 구간마다 그래디언트를 계산하기 때문에 계산 복잡도 감소
- 기울기 폭주 및 소실 문제 완화
RNN의 고질적인 문제
1. 하나의 Cell에서 모든 시퀀스 데이터 처리를 수행하기 때문에 시퀀스(t)의 크기가 커지면 앞쪽의 정보는 사라지게 된다.
2. 기울기 소실 현상이 일어날 수 있다.(하이퍼볼릭 탄젠트를 활성화 함수로 사용하기 때문)

에
LSTM (Long Short Term Memory)가 등장
기존 RNN에서 앞의 시퀀스에 중요한 정보가 있음에도 불구하고 뒤로 갈수록 그 정보가 소실되는 현상을
해결하기 위해 등장한 방식이다. 게이트를 이용하여 현 시점에 대한 정보와 이전 시점의 상태를 관리한다.
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
Understanding LSTM Networks -- colah's blog
Posted on August 27, 2015 <!-- by colah --> Humans don’t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking
colah.github.io
Christopher Olah가 2015년 8월에 쓴 글이다.
Home - colah's blog
colah.github.io
저자의 홈페이지 이다.
추후 천천히 공부해서 업로드 하겠다.
728x90
반응형
'경험 리뷰 > 한국경제 with Tossbank' 카테고리의 다른 글
| [패스트캠퍼스] 완강 후기 테디노트의 RAG 비법노트 : 랭체인을 활용한 GPT부터 로컬 모델까지의 RAG 가이드 (2) | 2024.12.15 |
|---|---|
| [ 논문 리뷰 ] Transformer - Attention Is All You Need(2017) [ 1 ] (21) | 2024.10.09 |
| 기본_LLM_Chain_( 1 ) (10) | 2024.09.21 |
| Deep Learning 공부하기 ( 2 ) (1) | 2024.09.19 |
| Deep Learning 공부하기 ( 1 ) (7) | 2024.09.19 |




