고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
1. 강의 주제: 기술 통계 (Descriptive Statistics)
1-1. 기술 통계 개요 (Overview of Descriptive Statistics)
기술 통계는 데이터를 요약하고 설명하는 방법입니다. 영화의 줄거리를 요약해서 설명하는 것과 비슷합니다. 전체 데이터를 통해 중요한 정보만 골라내어 이해하기 쉽게 보여주는 것이 목표입니다.
1-2. 중심 경향성 측정 (Measures of Central Tendency)
- 평균 (Mean)
평균은 모든 데이터를 더한 후 데이터의 개수로 나눈 값입니다. 마치 친구들과 나누어 먹을 피자를 시켜서 각 몇 조각씩 돌아가는지 계산하는 것처럼, 데이터의 중심값을 찾는 방법입니다. - 중앙값 (Median)
중앙값은 데이터를 크기 순으로 정렬했을 때 중간에 있는 값입니다. 마치 책장에 책을 키 순서대로 정리했을 때, 딱 중간에 있는 책 한 권을 찾는 것과 같습니다. - 최빈값 (Mode)
최빈값은 가장 자주 등장하는 값입니다. 가장 많이 나타나는 값을 찾습니다.
1-3. 변동성 측정 (Measures of Variability)
- 범위 (Range)
범위는 데이터의 최대값과 최소값의 차이입니다. 마치 농구 팀에서 키가 가장 큰 선수와 가장 작은 선수의 키 차이를 계산하는 것과 같습니다. - 분산 (Variance)
분산은 데이터가 평균에서 얼마나 퍼져 있는지를 나타냅니다. 마치 친구들끼리 시험 점수를 비교할 때, 각자 점수가 평균에서 얼마나 벗어나 있는지를 계산하는 것과 비슷합니다. - 표준 편차 (Standard Deviation)
표준 편차는 분산의 제곱근으로, 데이터가 평균을 중심으로 얼마나 퍼져 있는지 한 눈에 알기 쉽게 나타냅니다. 마치 도로에 있는 자동차들이 도로의 중앙선을 기준으로 얼마나 퍼져 있는지를 보는 것과 같습니다.
1-4. 왜도와 첨도 (Skewness and Kurtosis)
- 왜도 (Skewness)
왜도는 데이터의 비대칭 정도를 나타냅니다. 마치 한쪽으로 치우친 모래시계를 보는 것과 같습니다. 한쪽 방향으로 더 많은 모래가 쌓여 있는지 확인합니다. - 첨도 (Kurtosis)
첨도는 데이터의 뾰족한 정도를 나타냅니다. 마치 산의 정상부가 얼마나 뾰족한지를 보는 것과 같습니다. 데이터가 평균에 얼마나 집중되어 있는지를 보여줍니다.


1-5. 결론 (Conclusion)
기술 통계는 데이터를 요약하고 이해하기 쉽게 만드는 도구입니다. 친구들과의 대화에서 이야기를 요약해주는 것처럼, 기술 통계를 통해 데이터를 쉽게 이해할 수 있습니다.
2. 강의 주제: 그래프 작성 (Drawing Graphs)
2-1. 그래프 작성 개요 (Overview of Drawing Graphs)
그래프 작성은 데이터를 시각적으로 표현하여 쉽게 이해할 수 있도록 하는 방법입니다. 마치 복잡한 이야기를 그림으로 표현해 더 쉽게 이해하게 하는 것과 같습니다. 그래프는 데이터를 한눈에 파악할 수 있게 도와줍니다.
2-2. 기초 그래프 작성 (Basic Plotting)
- 선 그래프 (Line Graphs)
선 그래프는 데이터를 선으로 연결하여 변화 추이를 보여줍니다. 마치 날씨 일기를 기록하면서, 매일의 기온 변화를 선으로 연결해 한눈에 볼 수 있게 하는 것과 같습니다. - 막대 그래프 (Bar Graphs)
막대 그래프는 데이터를 막대로 표현하여 각 항목의 크기를 비교합니다. 마치 친구들 키를 막대로 그려서 누가 가장 큰지 쉽게 볼 수 있게 하는 것과 같습니다. - 히스토그램 (Histograms)
히스토그램은 데이터를 구간별로 나누어 빈도를 막대로 나타냅니다. 마치 도서관에서 책을 장르별로 나누어 몇 권씩 있는지 막대로 표현하는 것과 같습니다.
2-3. 산점도 (Scatter Plots)
산점도는 두 변수 간의 관계를 점으로 나타냅니다. 마치 학교 성적과 공부 시간을 각각 축으로 두고, 학생들의 점수를 점으로 찍어 관계를 보는 것과 같습니다. 어떤 학생이 공부를 많이 할수록 성적이 높은지 한눈에 파악할 수 있습니다.

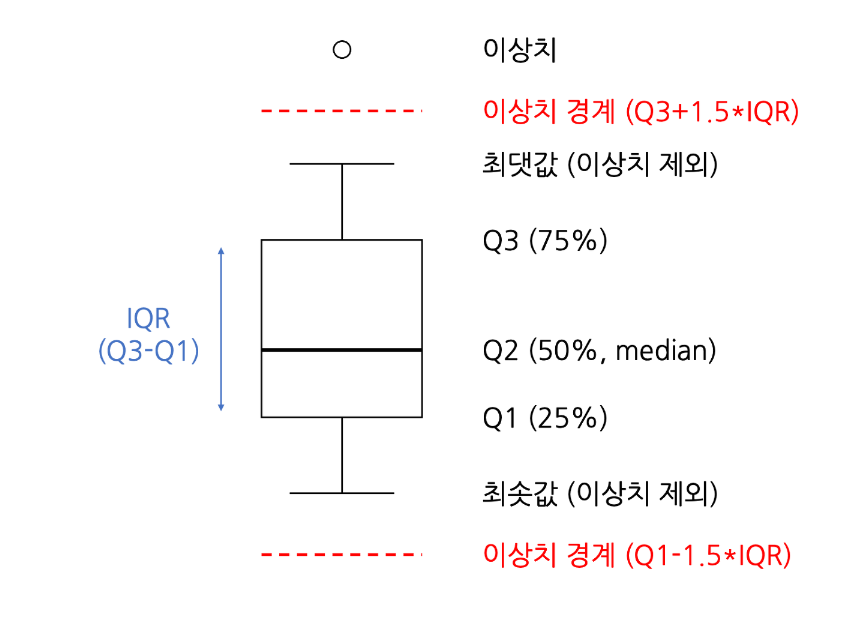
2-4. 상자 그림 (Box Plots)
상자 그림은 데이터의 분포를 시각적으로 나타냅니다. 마치 신발 상자를 여러 개 쌓아 놓고, 각 상자에 들어있는 신발 크기를 비교하는 것과 같습니다. 중앙값, 사분위수, 이상치를 한눈에 볼 수 있습니다.
2-5. 커널 밀도 추정 (Kernel Density Estimates)
커널 밀도 추정은 데이터의 분포를 부드럽게 나타내는 방법입니다. 마치 산의 윤곽을 부드러운 곡선으로 그려서, 산의 모양을 더 잘 이해할 수 있게 하는 것과 같습니다. 데이터가 어디에 집중되어 있는지를 보여줍니다.

2-6. 결론 (Conclusion)
그래프 작성은 데이터를 시각적으로 표현하여 쉽게 이해할 수 있게 도와줍니다. 마치 복잡한 이야기를 그림으로 그려서 이해를 돕는 것처럼, 그래프를 통해 데이터를 더 쉽게 파악할 수 있습니다.
3. 데이터 정리 (Data Wrangling)
3-1. 데이터 분석의 실용성 (Practicality of Data Analysis)
데이터를 효과적으로 다루고 분석하는 것은 요리를 맛있게 만드는 것과 비슷합니다. 적절한 도구와 방법을 사용하여 데이터에서 의미 있는 정보를 추출하는 것이 목표입니다.
3-2. 데이터 전처리 (Data Preprocessing)
- 결측치 처리 (Handling Missing Data)
- 결측치는 데이터 분석을 방해할 수 있는 요소입니다. 결측치를 처리하여 데이터의 완전성을 유지하고 정확한 분석을 할 수 있도록 합니다. + 결측치 : 데이터가 누락되어 있는 상태를 말합니다. 데이터 수집 과정에서 발생할 수 있는 문제로 인해 데이터 값이 존재하지 않는 경우를 의미합니다.
- 이상치 처리 (Outlier Treatment)
이상치는 데이터의 분석 결과에 영향을 줄 수 있는 요소입니다. 이상치를 발견하고 적절히 처리하여 데이터 분석의 정확성을 높이는 것이 중요합니다. + 이상치 : 대부분의 데이터와는 크게 다른 값을 가지는 데이터 포인트를 의미합니다. 이는 데이터 분석에서 주로 주의해야 할 부분이며, 분석 결과에 왜곡을 일으킬 수 있는 요소
3-3. 데이터 시각화와 해석 (Visualization and Interpretation)
적절한 그래프와 시각적 요소를 사용하여 데이터의 패턴을 파악하고 이해할 수 있습니다. 데이터를 시각적으로 표현하면 보다 쉽게 해석할 수 있습니다.
3-4. 모델링과 예측 (Modeling and Prediction)
모델링은 마치 요리 레시피를 따라 정확히 재료를 섞고 조리하여 최상의 결과물을 만드는 것과 비슷합니다. 데이터를 분석하여 모델을 구축하고 예측력을 갖추는 과정에서 적절한 알고리즘과 기법을 선택하는 것이 중요합니다. 데이터에서 패턴을 찾고 미래를 예측하는 것이 목표입니다.
3-5. 결론 (Conclusion)
데이터 분석은 실용적인 접근을 통해 데이터에서 유의미한 인사이트를 도출하는 것입니다. 마치 요리를 할 때 재료를 정확히 섞어서 맛있는 요리를 만드는 것과 같이, 데이터를 처리하고 분석하여 중요한 결론을 도출하는 과정입니다.
4. 강의 주제: 기본 프로그래밍 (Basic Programming)
4-1. 프로그래밍 기초 (Fundamentals of Programming)
올바른 순서와 방법으로 재료를 처리하고 요리하는 것처럼, 프로그래밍에서도 기본적인 개념과 문법을 이해하는 것이 중요합니다.
4-2. 변수와 데이터 타입 (Variables and Data Types)
- 변수 (Variables)
데이터를 저장하고 관리하는 데 사용되며, 필요할 때마다 값이 변경될 수 있습니다. 변수를 사용하여 데이터를 효율적으로 관리할 수 있습니다. - 데이터 타입 (Data Types)
데이터 타입은 마치 재료의 종류와 같습니다. 각각의 데이터 타입은 특정한 종류의 값을 저장하고 처리하는 방법을 정의합니다. 정수, 실수, 문자열 등 다양한 데이터 타입을 이해하고 적절히 활용하는 것이 중요합니다.
4-3. 조건문과 반복문 (Conditional Statements and Loops)
조건문 (Conditional Statements)
조건문은 마치 조리법의 순서와 같습니다. 특정 조건이 참인 경우에만 특정 작업을 수행하도록 프로그래밍할 수 있습니다. if-else 구문을 사용하여 조건에 따라 프로그램의 흐름을 제어할 수 있습니다.
+조건문 (Conditional Statements)
조건문은 특정 조건에 따라 프로그램의 흐름을 제어하는 구문입니다. 주로 if-else 구문을 사용합니다. 예를 들어, 학생의 시험 성적에 따라 합격 여부를 판단하는 프로그램을 작성해 보겠습니다.
score = 85
if score >= 90:
print("A grade")
elif score >= 80:
print("B grade")
elif score >= 70:
print("C grade")
else:
print("Fail")
반복문 (Loops)
반복문은 마치 동일한 작업을 반복해서 수행하는 것과 같습니다. for 루프와 while 루프를 사용하여 코드를 간결하게 작성하고 반복 작업을 자동화할 수 있습니다.
+ for 루프 예제
for i in range(1, 11):
print(i)
# 위 코드는 1부터 10까지의 숫자를 한 줄에 하나씩 출력합니다.
# range(1, 11)은 1부터 10까지의 숫자 범위를 나타냅니다.+ while 루프 예제
count = 1
while count <= 10:
print(count)
count += 1
# 위 코드는 변수 count가 1부터 시작하여 10까지 증가하면서 값을 출력합니다.
# count가 10이 되면 루프가 종료됩니다
반복문과 조건문의 결합 예제
반복문과 조건문을 함께 사용하여 특정 조건에 맞는 값을 찾거나 처리할 수 있습니다. 예를 들어, 1부터 100까지의 숫자 중에서 3의 배수인 숫자를 출력하는 프로그램을 작성해 보겠습니다.
for i in range(1, 101):
if i % 3 == 0:
print(i)
# 위 코드는 1부터 100까지의 숫자를 검사하여 3으로 나누어 떨어지는 숫자를 출력합니다.
# 즉, 3의 배수인 숫자만을 출력하게 됩니다.
4-4. 함수 (Functions)
함수는 한 부분을 독립적으로 만드는 것과 같습니다. 특정 작업을 수행하는 코드 블록을 함수로 정의하고 호출하여 재사용할 수 있습니다. 함수를 사용하여 프로그램을 구조화하고 유지보수성을 높이는 것이 중요합니다.
4-5. 파일 처리 (File Handling)
프로그램에서 데이터를 파일에 쓰거나 파일에서 데이터를 읽어와 처리하는 방법을 배웁니다. 파일을 효율적으로 다루어 데이터를 영구적으로 저장하고 관리할 수 있습니다.
4-6. 결론 (Conclusion)
프로그래밍을 통해 문제를 해결하고 다양한 기술을 개발할 수 있는 능력을 키우는 것이 목표입니다.
출처 : https://ethanweed.github.io/pythonbook/03.01-descriptives.html
728x90
반응형
'경험 리뷰 > 한국경제 with Tossbank' 카테고리의 다른 글
| [K-Digital Training] 한국경제신문 with toss bank (한달 후기) (1) | 2024.07.31 |
|---|---|
| Python 으로 통계 학습하기 - 통계 이론 (1) | 2024.07.13 |
| MY SQL - SQL 실전 문제 ( 1 ) (0) | 2024.07.12 |
| MY SQL - SQL 기초 문법 ( 2 ) (1) | 2024.07.12 |
| MY SQL - 데이터베이스와 SQL ( 1 ) (1) | 2024.07.11 |




