고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
[K-Digital Training] 한국경제신문 with toss bank


import gdown # gdown이라는 도구를 가져와요
!pip install gdown # gdown을 설치해요
# 인터넷에서 파일을 다운로드해요
gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet=False)
# 'https://bit.ly/3pK7iuu' 링크에서 'ns_book7.csv'라는 이름으로 파일을 다운로드해요
# quiet=False는 다운로드 과정을 자세히 보여주는 설정이에요

import pandas as pd # pandas를 pd라는 이름으로 가져와요
# 파일을 읽어와 데이터프레임으로 저장해요
ns_book7 = pd.read_csv('ns_book7.csv', low_memory=False)
# 'ns_book7.csv' 파일을 읽어서 ns_book7이라는 데이터프레임으로 저장해요
# low_memory=False는 메모리를 적게 사용하기 위한 설정이에요
# 출판사의 대출 건수를 세어서 상위 30개 출판사를 뽑아내요
top30_pubs = ns_book7['출판사'].value_counts()[:30]
# ns_book7 데이터프레임에서 상위 30개 출판사만 골라내요
top30_pubs_idx = ns_book7['출판사'].isin(top30_pubs.index)
# 상위 30개 출판사의 출판사, 발행년도, 대출건수 열만 선택해요
ns_book9 = ns_book7[top30_pubs_idx][['출판사', '발행년도', '대출건수']]
# 출판사와 발행년도별로 그룹을 나누고 대출건수를 더해요
ns_book9 = ns_book9.groupby(by=['출판사', '발행년도']).sum()
# 그룹화된 결과를 다시 데이터프레임으로 만들어요
ns_book9 = ns_book9.reset_index()

import seaborn as sns # seaborn이라는 도구를 가져와요
import matplotlib.pyplot as plt # matplotlib의 pyplot을 plt라는 이름으로 가져와요
plt.rcParams['font.family'] = 'Malgun Gothic' # 한글 폰트를 설정해요
fig, ax = plt.subplots(figsize=(8, 6)) # 그래프를 그릴 도화지를 만들어요, 크기는 가로 8, 세로 6으로 해요
# 상위 16개 출판사의 데이터를 그려요
for pub in top30_pubs.index[:16]:
line = ns_book9[ns_book9['출판사'] == pub] # 각 출판사의 데이터를 가져와요
ax.plot(line['발행년도'], line['대출건수'], label=pub) # 출판사별로 발행년도와 대출건수를 그래프로 그려요
ax.set_title('년도별 대출건수') # 그래프 제목을 설정해요
ax.legend() # 그래프에 범례를 추가해요
ax.set_xlim(1985, 2025) # x축의 범위를 1985년부터 2025년으로 설정해요
plt.show() # 그래프를 화면에 보여줘요

fig, ax = plt.subplots(4, 4, figsize=(16, 10)) # 4x4 크기의 그래프 배열을 만들어요. 크기는 가로 16, 세로 10이에요
# 상위 16개 출판사의 데이터를 그려요
for i, pub in enumerate(top30_pubs.index[:16]):
line = ns_book9[ns_book9['출판사'] == pub] # 각 출판사의 데이터를 가져와요
if i <= 3: # 첫 번째 행에 그래프를 그려요
ax[0, i].plot(line['발행년도'], line['대출건수'], label=pub)
ax[0, i].set_title(f'{pub} 년도별 대출건수') # 그래프 제목을 설정해요
ax[0, i].set_xlim(1985, 2025) # x축 범위를 설정해요
elif i <= 7: # 두 번째 행에 그래프를 그려요
ax[1, i-4].plot(line['발행년도'], line['대출건수'], label=pub)
ax[1, i-4].set_title(f'{pub} 년도별 대출건수')
ax[1, i-4].set_xlim(1985, 2025)
elif i <= 11: # 세 번째 행에 그래프를 그려요
ax[2, i-8].plot(line['발행년도'], line['대출건수'], label=pub)
ax[2, i-8].set_title(f'{pub} 년도별 대출건수')
ax[2, i-8].set_xlim(1985, 2025)
else: # 네 번째 행에 그래프를 그려요
ax[3, i-12].plot(line['발행년도'], line['대출건수'], label=pub)
ax[3, i-12].set_title(f'{pub} 년도별 대출건수')
ax[3, i-12].set_xlim(1985, 2025)
plt.tight_layout(rect=[0, 0.03, 1, 0.95]) # 그래프들 사이의 간격을 자동으로 조절해요
plt.show() # 모든 그래프를 화면에 보여줘요


# 4x4 서브플롯 생성
fig, axes = plt.subplots(4, 4, figsize=(16, 10)) # 4x4 크기의 그래프 배열을 만들어요. 크기는 가로 16, 세로 10이에요
fig.suptitle('년도별 대출건수', fontsize=20) # 그래프 전체 제목을 설정해요
# 상위 16개 출판사별로 그래프 생성
for i, pub in enumerate(top30_pubs.index[:16]):
if i < 16: # 상위 16개 출판사를 대상으로 해요
row = i // 4 # 행을 계산해요
col = i % 4 # 열을 계산해요
ax = axes[row, col] # 해당 위치의 서브플롯을 선택해요
line = ns_book9[ns_book9['출판사'] == pub] # 각 출판사의 데이터를 가져와요
ax.plot(line['발행년도'], line['대출건수'], label=pub) # 출판사별로 발행년도와 대출건수를 그래프로 그려요
ax.set_title(pub) # 서브플롯 제목을 설정해요
ax.set_xlim(1985, 2025) # x축 범위를 설정해요
plt.tight_layout(rect=[0, 0.03, 1, 0.95]) # 그래프들 사이의 간격을 자동으로 조절해요
plt.show() # 모든 그래프를 화면에 보여줘요


# 대출건수가 10 이상인 도서들을 필터링
filtered_books = ns_book7[ns_book7['대출건수'] >= 10]
# ns_book7 데이터프레임에서 '대출건수'가 10 이상인 도서들만 필터링해서 filtered_books 데이터프레임으로 저장해요
# 필터링된 데이터 확인
filtered_books.head()
# 필터링된 데이터프레임의 첫 5개 행을 확인해요

# 대출건수가 10 이상인 도서들을 필터링하고 인덱스를 초기화한 후 데이터의 형태를 확인
filtered_books_shape = ns_book7.loc[ns_book7['대출건수'] >= 10, :].reset_index(drop=True).shape
# ns_book7 데이터프레임에서 '대출건수'가 10 이상인 도서들만 필터링하고, 인덱스를 초기화한 후 그 데이터의 형태를 filtered_books_shape에 저장해요
filtered_books_shape # 필터링된 데이터의 형태(행과 열의 개수)를 출력해요

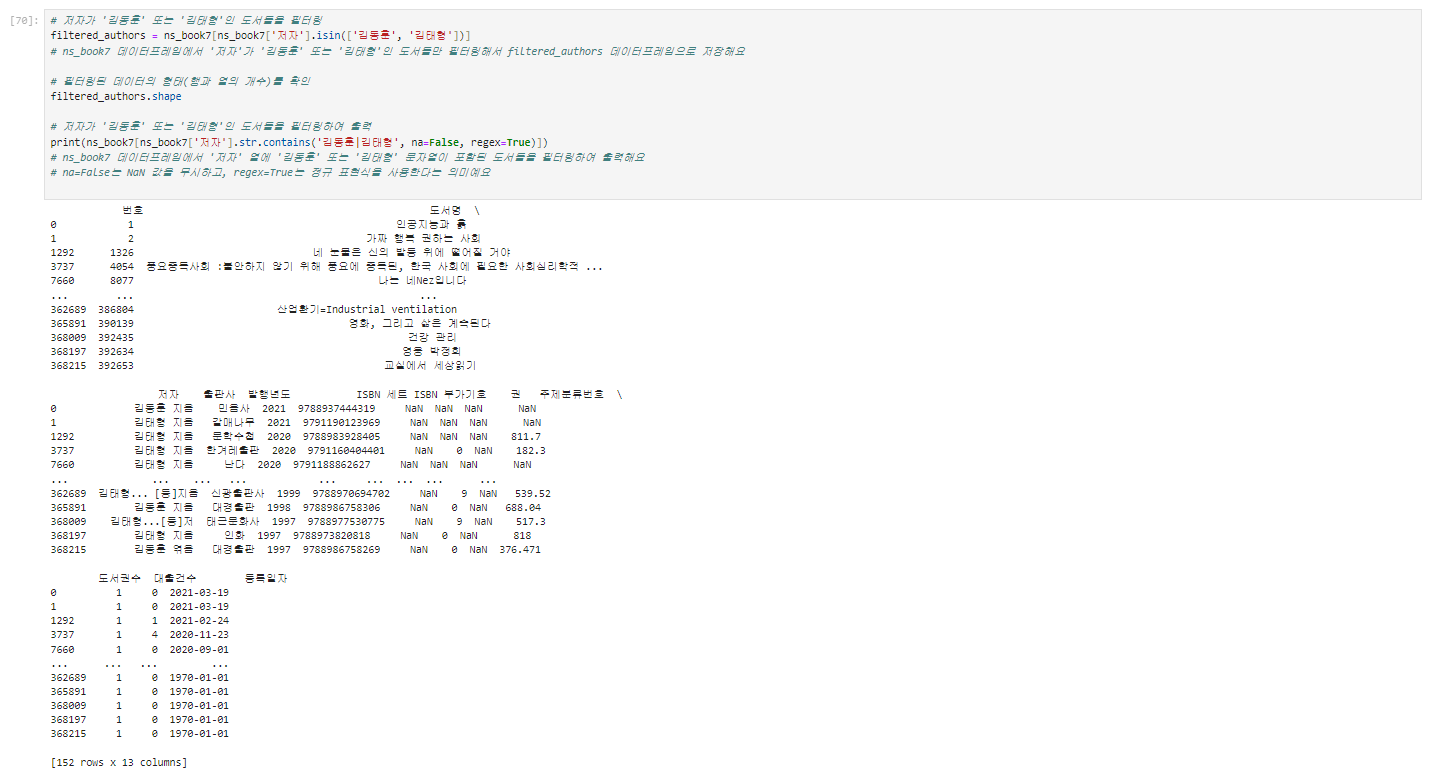
# 저자가 '김동훈' 또는 '김태형'인 도서들을 필터링
filtered_authors = ns_book7[ns_book7['저자'].isin(['김동훈', '김태형'])]
# ns_book7 데이터프레임에서 '저자'가 '김동훈' 또는 '김태형'인 도서들만 필터링해서 filtered_authors 데이터프레임으로 저장해요
# 필터링된 데이터의 형태(행과 열의 개수)를 확인
filtered_authors.shape
# 저자가 '김동훈' 또는 '김태형'인 도서들을 필터링하여 출력
print(ns_book7[ns_book7['저자'].str.contains('김동훈|김태형', na=False, regex=True)])
# ns_book7 데이터프레임에서 '저자' 열에 '김동훈' 또는 '김태형' 문자열이 포함된 도서들을 필터링하여 출력해요
# na=False는 NaN 값을 무시하고, regex=True는 정규 표현식을 사용한다는 의미예요

# 저자가 '김동훈' 또는 '김태형'인 도서들을 필터링하고 인덱스를 초기화한 후 데이터의 형태를 확인
filtered_authors_shape = ns_book7.loc[ns_book7['저자'].isin(['김동훈', '김태형']), :].reset_index(drop=True).shape
# ns_book7 데이터프레임에서 '저자'가 '김동훈' 또는 '김태형'인 도서들만 필터링하고, 인덱스를 초기화한 후 그 데이터의 형태를 filtered_authors_shape에 저장해요
filtered_authors_shape # 필터링된 데이터의 형태(행과 열의 개수)를 출력해요
# 저자가 '김동훈' 또는 '김태형'인 도서들을 필터링하여 출력
print(ns_book7[ns_book7['저자'].str.contains('김동훈|김태형', na=False, regex=True)])
# ns_book7 데이터프레임에서 '저자' 열에 '김동훈' 또는 '김태형' 문자열이 포함된 도서들을 필터링하여 출력해요
# na=False는 NaN 값을 무시하고, regex=True는 정규 표현식을 사용한다는 의미예요


# 발행년도가 2020년 이상이고 대출건수가 5 이상인 도서들을 필터링
filtered_books = ns_book7[(ns_book7['발행년도'] >= 2020) & (ns_book7['대출건수'] >= 5)]
# ns_book7 데이터프레임에서 '발행년도'가 2020년 이상이고 '대출건수'가 5 이상인 도서들만 필터링해서 filtered_books 데이터프레임으로 저장해요
# 필터링된 데이터 확인
filtered_books.head()
# 필터링된 데이터프레임의 첫 5개 행을 확인해요

# 발행년도가 2020년 이상이고 대출건수가 5 이상인 도서들을 필터링하고 인덱스를 초기화한 후 데이터의 형태를 확인
filtered_books_shape = ns_book7.loc[(ns_book7['발행년도'] >= 2020) & (ns_book7['대출건수'] >= 5), :].reset_index(drop=True).shape
# ns_book7 데이터프레임에서 '발행년도'가 2020년 이상이고 '대출건수'가 5 이상인 도서들만 필터링하고,
# 인덱스를 초기화한 후 그 데이터의 형태를 filtered_books_shape에 저장해요
filtered_books_shape # 필터링된 데이터의 형태(행과 열의 개수)를 출력해요


# 대출건수가 5 이상인 도서들의 도서명을 대문자로 변환하고 새로운 컬럼 추가
ns_book7['도서명 + 5건이상'] = ns_book7.apply(
lambda row: f"*** {row['도서명'].upper()} ***" if row['대출건수'] >= 5 else row['도서명'],
axis=1
)
# ns_book7 데이터프레임에 '도서명 + 5건이상'이라는 새로운 컬럼을 추가해요
# '대출건수'가 5 이상인 도서의 '도서명'을 대문자로 변환하고, 앞뒤에 ***을 붙여요
# '대출건수'가 5 미만인 도서는 '도서명'을 그대로 사용해요
# apply 함수와 lambda 함수를 사용해 행 단위로 조건을 적용해요
# 결과 확인
ns_book7.head()
# 변경된 데이터프레임의 첫 5개 행을 확인해요

# 대출건수가 5 이상인 도서들의 도서명을 대문자로 변환하고 새로운 컬럼 추가
ns_book7['도서명 + 5건이상'] = ns_book7['도서명'] # 새로운 컬럼을 기존 도서명으로 초기화해요
ns_book7.loc[ns_book7['대출건수'] >= 5.0, '도서명 + 5건이상'] = ns_book7.loc[ns_book7['대출건수'] >= 5.0, '도서명'].apply(lambda x: "*** " + x.upper() + " ***")
# '대출건수'가 5 이상인 도서들의 '도서명'을 대문자로 변환하고 앞뒤에 ***을 추가해요
# 결과 확인
ns_book7.head()
# 변경된 데이터프레임의 첫 5개 행을 확인해요


# 대출건수가 4와 5인 도서들을 필터링
filtered_books_4_5 = ns_book7[ns_book7['대출건수'].isin([4, 5])]
# ns_book7 데이터프레임에서 '대출건수'가 4 또는 5인 도서들만 필터링해서 filtered_books_4_5 데이터프레임으로 저장해요
# 필터링된 데이터 확인
filtered_books_4_5
# 필터링된 데이터프레임을 확인해요

# 대출건수가 4와 5인 도서들을 필터링하고 인덱스를 초기화
filtered_books_4_5_reset = ns_book7.loc[ns_book7['대출건수'].isin([4.0, 5.0]), :].reset_index(drop=True)
# ns_book7 데이터프레임에서 '대출건수'가 4 또는 5인 도서들만 필터링하고, 인덱스를 초기화해서 filtered_books_4_5_reset 데이터프레임으로 저장해요
# 필터링된 데이터 확인
filtered_books_4_5_reset
# 필터링된 데이터프레임을 확인해요


# 저자 컬럼에서 '류시화'가 포함된 행만 추출
filtered_authors_ryu = ns_book7[ns_book7['저자'].str.contains('류시화', na=False)]
# ns_book7 데이터프레임에서 '저자' 열에 '류시화'가 포함된 행들만 필터링해서 filtered_authors_ryu 데이터프레임으로 저장해요
# na=False는 NaN 값을 무시하고, str.contains는 특정 문자열이 포함된 행을 찾는 함수예요
# 필터링된 데이터 확인
filtered_authors_ryu
# 필터링된 데이터프레임을 확인해요

# 저자 컬럼에서 '류시화'가 포함된 행만 추출하고 인덱스를 초기화
filtered_authors_ryu_reset = ns_book7[ns_book7['저자'].str.contains('류시화')].reset_index(drop=True)
# ns_book7 데이터프레임에서 '저자' 열에 '류시화'가 포함된 행들만 필터링하고, 인덱스를 초기화해서 filtered_authors_ryu_reset 데이터프레임으로 저장해요
# 필터링된 데이터 확인
filtered_authors_ryu_reset
# 필터링된 데이터프레임을 확인해요


# '저자' 컬럼에서 '류시화'를 '시화 류'로 변경하고 새로운 컬럼에 저장
ns_book7['저자변경'] = ns_book7['저자'].apply(lambda x: '시화 류' if '류시화' in x else x)
# '저자' 열의 값이 '류시화'를 포함하고 있으면 '시화 류'로 바꾸고, 그렇지 않으면 원래 값을 그대로 사용해 '저자변경' 컬럼에 저장해요
# '저자변경' 컬럼에서 '시화 류'가 포함된 행을 추출하고 인덱스를 초기화
filtered_authors_changed = ns_book7[ns_book7['저자변경'].str.contains('시화 류')].reset_index(drop=True)
# ns_book7 데이터프레임에서 '저자변경' 열에 '시화 류'가 포함된 행들만 필터링하고, 인덱스를 초기화해서 filtered_authors_changed 데이터프레임으로 저장해요
# 필터링된 데이터 확인
filtered_authors_changed
# 필터링된 데이터프레임을 확인해요

# '저자' 컬럼에서 '류시화'를 '시화 류'로 변경하고 새로운 컬럼에 저장
ns_book7['저자변경2'] = ns_book7['저자'].apply(lambda x: x.replace('류시화', '시화 류'))
# '저자' 열의 값에서 '류시화'를 '시화 류'로 바꿔서 '저자변경2' 컬럼에 저장해요
# '저자변경2' 컬럼에서 '시화 류'가 포함된 행을 추출하고 인덱스를 초기화
filtered_authors_changed2 = ns_book7[ns_book7['저자변경2'].str.contains('시화 류')].reset_index(drop=True)
# ns_book7 데이터프레임에서 '저자변경2' 열에 '시화 류'가 포함된 행들만 필터링하고, 인덱스를 초기화해서 filtered_authors_changed2 데이터프레임으로 저장해요
# 필터링된 데이터 확인
filtered_authors_changed2
# 필터링된 데이터프레임을 확인해요728x90
반응형
'경험 리뷰 > 한국경제 with Tossbank' 카테고리의 다른 글
| 2024.07.09 / SQL, Pandas - 기초 문법 비교 / (1) (0) | 2024.07.09 |
|---|---|
| 2024.07.08 / Pandas - 기본 문법, 시각화 / 문제 분석 (6) (1) | 2024.07.08 |
| 2024.07.04 / Pandas - 시각화 / 문제 분석 (4) (0) | 2024.07.04 |
| 2024.07.03 / Pandas - kaggle 데이터 사용하기. / 문제 분석 (3) (1) | 2024.07.04 |
| 2024.07.03 / Pandas - apply, lambda / 문제 분석 (2) (0) | 2024.07.03 |




